
# Colly 介绍
colly 是 Go 实现的比较有名的一款爬虫框架,而且 Go 在高并发和分布式场景的优势也正是爬虫技术所需要的。它的主要特点是轻量、快速,设计非常优雅,并且分布式的支持也非常简单,易于扩展。
官网地址:http://go-colly.org/
包地址:import "github.com/gocolly/colly"
# 安装
go get -u github.com/gocolly/colly/...
一个简单的例子:
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("a", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.Visit("http://go-colly.org/")
}
使用方式概括下来主要有三步:
- 创建一个采集器
- 注册回调函数
- 访问具体网站
创建采集器时可以指定一些配置参数,如useragent,爬取深度及日志等
colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"),
colly.MaxDepth(1),
colly.Debugger(&debug.LogDebugger{}))
回调函数共有7 种
| 名称 | 说明 | 参数1 | 参数2 |
|---|---|---|---|
| OnRequest | 请求前调用 | *colly.Request | |
| OnError | 请求发生错误时调用 | *colly.Response | error |
| OnResponseHeaders | 收到响应头后调用 | colly.Response | |
| OnResponse | 收到响应后调用 | colly.Response | |
| OnHTML | 响应内容是HTML时调用 | xpath表达式 | func(e *colly.HTMLElement) |
| OnXML | 响应内容是XML时调用 | xpath表达式 | func(e *colly.XMLElement) |
| OnScraped | 在OnXML之后调用 | func(r *colly.Response) |
OnHTML回调可以注册多个,匹配不同的xpath表达式
# 1. 爬取简书首页文章列表
通过浏览器开发者工具查看jianshu.com结构如下
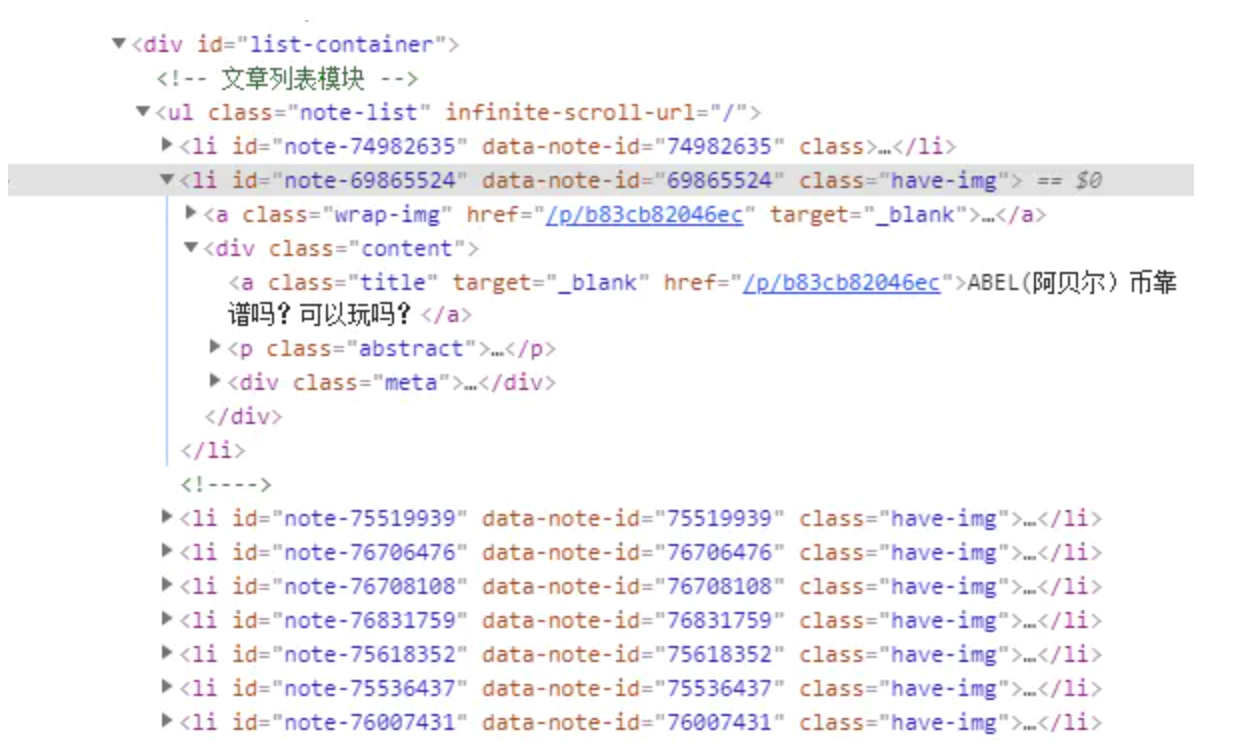
文章列表为ul标签,中间每一项是li标签,li中包含content,content中包含title,abstract和meta标签
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/debug"
)
func main() {
c := colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"), colly.MaxDepth(1), colly.Debugger(&debug.LogDebugger{}))
//文章列表
c.OnHTML("ul[class='note-list']", func(e *colly.HTMLElement) {
//列表中每一项
e.ForEach("li", func(i int, item *colly.HTMLElement) {
//文章链接
href := item.ChildAttr("div[class='content'] > a[class='title']", "href")
//文章标题
title := item.ChildText("div[class='content'] > a[class='title']")
//文章摘要
summary := item.ChildText("div[class='content'] > p[class='abstract']")
fmt.Println(title, href)
fmt.Println(summary)
fmt.Println()
})
})
err := c.Visit("https://www.jianshu.com")
if err != nil {
fmt.Println(err.Error())
}
}
# 2.爬取文章列表和详情
文章列表和1方式一样,文章详情通过创建新的采集器访问详情页面
package main
import (
"fmt"
"github.com/gocolly/colly"
"time"
)
func main() {
c1 := colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"), colly.MaxDepth(1))
c2 := c1.Clone()
//异步
c2.Async = true
//限速
c2.Limit(&colly.LimitRule{
DomainRegexp: "",
DomainGlob: "*.jianshu.com/p/*",
Delay: 10 * time.Second,
RandomDelay: 0,
Parallelism: 1,
})
//采集器1,获取文章列表
c1.OnHTML("ul[class='note-list']", func(e *colly.HTMLElement) {
e.ForEach("li", func(i int, item *colly.HTMLElement) {
href := item.ChildAttr("div[class='content'] > a[class='title']", "href")
title := item.ChildText("div[class='content'] > a[class='title']")
summary := item.ChildText("div[class='content'] > p[class='abstract']")
ctx := colly.NewContext()
ctx.Put("href", href)
ctx.Put("title", title)
ctx.Put("summary", summary)
//通过Context上下文对象将采集器1采集到的数据传递到采集器2
c2.Request("GET", "https://www.jianshu.com" + href, nil, ctx, nil)
})
})
//采集器2,获取文章详情
c2.OnHTML("article", func(e *colly.HTMLElement) {
href := e.Request.Ctx.Get("href")
title := e.Request.Ctx.Get("title")
summary := e.Request.Ctx.Get("summary")
detail := e.Text
fmt.Println("----------" + title + "----------")
fmt.Println(href)
fmt.Println(summary)
fmt.Println(detail)
fmt.Println()
})
c2.OnRequest(func(r *colly.Request) {
fmt.Println("c2爬取页面:", r.URL)
})
c1.OnRequest(func(r *colly.Request) {
fmt.Println("c1爬取页面:", r.URL)
})
c1.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
err := c1.Visit("https://www.jianshu.com")
if err != nil {
fmt.Println(err.Error())
}
c2.Wait()
}
# 3. 爬取需要登录的网页
官网提供登录页处理的例子,但是大多数涉及验证码,不好处理,目前方式是手动登录,复制cookie写到爬虫请求头里
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/debug"
"github.com/gocolly/colly/extensions"
_ "github.com/gocolly/colly/extensions"
"net/http"
)
func main() {
url := "https://www.jianshu.com"
c := colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"), colly.MaxDepth(1), colly.Debugger(&debug.LogDebugger{}))
c.OnHTML("ul[class='note-list']", func(e *colly.HTMLElement) {
e.ForEach("li", func(i int, item *colly.HTMLElement) {
href := item.ChildAttr("div[class='content'] > a[class='title']", "href")
title := item.ChildText("div[class='content'] > a[class='title']")
summary := item.ChildText("div[class='content'] > p[class='abstract']")
fmt.Println(title, href)
fmt.Println(summary)
fmt.Println()
})
})
//设置随机useragent
extensions.RandomUserAgent(c)
//设置登录cookie
c.SetCookies(url, []*http.Cookie{
&http.Cookie{
Name: "remember_user_token",
Value: "wNDUxOV0sIiQyYSQxMSRwdkhqWVhHYmxXaDJ6dEU3NzJwbmsuIiwiMTU",
Path: "/",
Domain: ".jianshu.com",
Secure: true,
HttpOnly: true,
},
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("爬取页面:", r.URL)
})
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
err := c.Visit(url)
if err != nil {
fmt.Println(err.Error())
}
}
# 4. 内存任务队列
将需要爬取的连接放入队列中,设置队列并发数,可以并行爬取连接
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/debug"
"github.com/gocolly/colly/queue"
)
func main() {
c := colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"), colly.MaxDepth(3), colly.Debugger(&debug.LogDebugger{}))
//创建内存队列,大小10000,goroutine数量 5
q, _ := queue.New(5, &queue.InMemoryQueueStorage{MaxSize: 10000})
c.OnHTML("a", func(element *colly.HTMLElement) {
element.Request.Visit(element.Attr("href"))
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("爬取页面:", r.URL)
})
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
q.AddURL("https://www.jianshu.com")
q.Run(c)
}
# 5. redis任务队列
设置redis存储后,队列中URL存储在redis中,访问页面的cookie及访问记录也会保存在redis中
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/debug"
"github.com/gocolly/colly/queue"
"github.com/gocolly/redisstorage"
)
func main() {
c := colly.NewCollector(colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"), colly.MaxDepth(3), colly.Debugger(&debug.LogDebugger{}))
storage := &redisstorage.Storage{
Address: "192.168.1.10:6379",
Password: "123456",
DB: 0,
Prefix: "colly",
Client: nil,
Expires: 0,
}
c.SetStorage(storage)
err := storage.Clear()
if err != nil{
panic(err)
}
defer storage.Client.Close()
q, _ := queue.New(5, storage)
c.OnHTML("a", func(element *colly.HTMLElement) {
element.Request.Visit(element.Attr("href"))
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("爬取页面:", r.URL)
})
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
q.AddURL("https://www.jianshu.com")
q.Run(c)
}

redis中数据
# 6.配置代理
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
"github.com/gocolly/colly/proxy"
)
func main() {
c := colly.NewCollector()
//配置两个代理
rp, err := proxy.RoundRobinProxySwitcher("http://127.0.0.1:1080", "socks5://127.0.0.1:1338")
if err != nil {
log.Fatal(err)
}
c.SetProxyFunc(rp)
c.OnResponse(func(r *colly.Response) {
log.Printf("%s\n", bytes.Replace(r.Body, []byte("\n"), nil, -1))
})
c.Visit("https://httpbin.org/ip")
}
作者:写个代码容易么 链接:https://www.jianshu.com/p/24151de59175 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
# colly 相关文章
# go爬虫框架colly源码以及软件架构分析
无意中发现了colly,我一直是使用python进行爬虫的, 学习golang的使用, 用go参考scrapy架构写了一个爬虫的框架demo。我一直以为go不适合做爬虫, go的领域是后端服务。然后去搜索了一下colly, 发现还是很流行。 我个人还是比较喜欢爬虫, 网络上的数据就是公开的API, 所以, 爬虫去请求接口获取数据。当然我是遵循君子协议的。
好, 下面进入正题,介绍colly
# colly介绍
Lightning Fast and Elegant Scraping Framework for Gophers
Colly provides a clean interface to write any kind of crawler/scraper/spider.
官方的介绍,gocolly快速优雅,在单核上每秒可以发起1K以上请求;以回调函数的形式提供了一组接口,可以实现任意类型的爬虫;依赖goquery库可以像jquery一样选择web元素。
# 安装使用
go get -u github.com/gocolly/colly/...
import "github.com/gocolly/colly"
# 架构特点
了解爬虫的都知道一个爬虫请求的生命周期
- 构建请求
- 发送请求
- 获取文档或数据
- 解析文档或清洗数据
- 数据处理或持久化
scrapy的设计理念是将上面的每一个步骤抽离出来,然后做出组件的形式, 最后通过调度组成流水线的工作形式。 我们看一下scrapy的架构图, 这里只是简单的介绍下, 后面有时间,我深入介绍scrapy

如图,downloader负责请求获取页面,spiders中写具体解析文档的逻辑,item PipeLine数据最后处理, 中间有一些中间件,可以一些功能的装饰。比如,代理,请求频率等。
我们介绍一下colly的架构特点 colly的逻辑更像是面向过程编程的, colly的逻辑就是按上面生命周期的顺序管道处理, 只是在不同阶段,加上回调函数进行过滤的时候进行处理。

下面也按照这个逻辑进行介绍
# 源码分析
先给一个🌰
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(
// Visit only domains: hackerspaces.org, wiki.hackerspaces.org
colly.AllowedDomains("hackerspaces.org", "wiki.hackerspaces.org"),
)
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))
})
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
// Start scraping on https://hackerspaces.org
c.Visit("https://hackerspaces.org/")
}
这是官方给的示例, 可以看到colly.NewCollector创建一个收集器, colly的所有处理逻辑都是以Collector为核心进行操作的。
我们看一下 Collector结构体的定义
// Collector provides the scraper instance for a scraping job
type Collector struct {
// UserAgent is the User-Agent string used by HTTP requests
UserAgent string
// MaxDepth limits the recursion depth of visited URLs.
// Set it to 0 for infinite recursion (default).
MaxDepth int
// AllowedDomains is a domain whitelist.
// Leave it blank to allow any domains to be visited
AllowedDomains []string
// DisallowedDomains is a domain blacklist.
DisallowedDomains []string
// DisallowedURLFilters is a list of regular expressions which restricts
// visiting URLs. If any of the rules matches to a URL the
// request will be stopped. DisallowedURLFilters will
// be evaluated before URLFilters
// Leave it blank to allow any URLs to be visited
DisallowedURLFilters []*regexp.Regexp
// URLFilters is a list of regular expressions which restricts
// visiting URLs. If any of the rules matches to a URL the
// request won't be stopped. DisallowedURLFilters will
// be evaluated before URLFilters
// Leave it blank to allow any URLs to be visited
URLFilters []*regexp.Regexp
// AllowURLRevisit allows multiple downloads of the same URL
AllowURLRevisit bool
// MaxBodySize is the limit of the retrieved response body in bytes.
// 0 means unlimited.
// The default value for MaxBodySize is 10MB (10 * 1024 * 1024 bytes).
MaxBodySize int
// CacheDir specifies a location where GET requests are cached as files.
// When it's not defined, caching is disabled.
CacheDir string
// IgnoreRobotsTxt allows the Collector to ignore any restrictions set by
// the target host's robots.txt file. See http://www.robotstxt.org/ for more
// information.
IgnoreRobotsTxt bool
// Async turns on asynchronous network communication. Use Collector.Wait() to
// be sure all requests have been finished.
Async bool
// ParseHTTPErrorResponse allows parsing HTTP responses with non 2xx status codes.
// By default, Colly parses only successful HTTP responses. Set ParseHTTPErrorResponse
// to true to enable it.
ParseHTTPErrorResponse bool
// ID is the unique identifier of a collector
ID uint32
// DetectCharset can enable character encoding detection for non-utf8 response bodies
// without explicit charset declaration. This feature uses https://github.com/saintfish/chardet
DetectCharset bool
// RedirectHandler allows control on how a redirect will be managed
RedirectHandler func(req *http.Request, via []*http.Request) error
// CheckHead performs a HEAD request before every GET to pre-validate the response
CheckHead bool
store storage.Storage
debugger debug.Debugger
robotsMap map[string]*robotstxt.RobotsData
htmlCallbacks []*htmlCallbackContainer
xmlCallbacks []*xmlCallbackContainer
requestCallbacks []RequestCallback
responseCallbacks []ResponseCallback
errorCallbacks []ErrorCallback
scrapedCallbacks []ScrapedCallback
requestCount uint32
responseCount uint32
backend *httpBackend
wg *sync.WaitGroup
lock *sync.RWMutex
}
上面的具体属性我就不介绍了, 看看注释也就懂了。 我就先按上面的示例解释源码
// 创建一个 Collector对象
c := colly.NewCollector(
// Visit only domains: hackerspaces.org, wiki.hackerspaces.org
colly.AllowedDomains("hackerspaces.org", "wiki.hackerspaces.org"),
)
// 添加一个HTML的回调函数
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))
})
// 添加一个 Requset回调函数
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
// 开始爬取
c.Visit("https://hackerspaces.org/")
回调函数如何用? 什么作用? 先卖个关子, c.Visit("https://hackerspaces.org/")是入口, 那就先分析它,
// Visit starts Collector's collecting job by creating a
// request to the URL specified in parameter.
// Visit also calls the previously provided callbacks
func (c *Collector) Visit(URL string) error {
if c.CheckHead {
if check := c.scrape(URL, "HEAD", 1, nil, nil, nil, true); check != nil {
return check
}
}
return c.scrape(URL, "GET", 1, nil, nil, nil, true)
}
👆又出来一个新的method,
func (c *Collector) scrape(u, method string, depth int, requestData io.Reader, ctx *Context, hdr http.Header, checkRevisit bool) error {
// 检查请求是否合法
if err := c.requestCheck(u, method, depth, checkRevisit); err != nil {
return err
}
// 解析url,
parsedURL, err := url.Parse(u)
if err != nil {
return err
}
if parsedURL.Scheme == "" {
parsedURL.Scheme = "http"
}
if !c.isDomainAllowed(parsedURL.Hostname()) {
return ErrForbiddenDomain
}
// robots协议
if method != "HEAD" && !c.IgnoreRobotsTxt {
if err = c.checkRobots(parsedURL); err != nil {
return err
}
}
// headers
if hdr == nil {
hdr = http.Header{"User-Agent": []string{c.UserAgent}}
}
rc, ok := requestData.(io.ReadCloser)
if !ok && requestData != nil {
rc = ioutil.NopCloser(requestData)
}
// The Go HTTP API ignores "Host" in the headers, preferring the client
// to use the Host field on Request.
host := parsedURL.Host
if hostHeader := hdr.Get("Host"); hostHeader != "" {
host = hostHeader
}
// 构造http.Request
req := &http.Request{
Method: method,
URL: parsedURL,
Proto: "HTTP/1.1",
ProtoMajor: 1,
ProtoMinor: 1,
Header: hdr,
Body: rc,
Host: host,
}
// 请求的数据(requestData)转换成io.ReadCloser接口数据
setRequestBody(req, requestData)
u = parsedURL.String()
c.wg.Add(1)
// 异步方式
if c.Async {
go c.fetch(u, method, depth, requestData, ctx, hdr, req)
return nil
}
return c.fetch(u, method, depth, requestData, ctx, hdr, req)
}
上面很大篇幅都是检查, 现在还在 request的阶段, 还没有response,看c.fetch
fetch就是colly的核心内容
func (c *Collector) fetch(u, method string, depth int, requestData io.Reader, ctx *Context, hdr http.Header, req *http.Request) error {
defer c.wg.Done()
if ctx == nil {
ctx = NewContext()
}
request := &Request{
URL: req.URL,
Headers: &req.Header,
Ctx: ctx,
Depth: depth,
Method: method,
Body: requestData,
collector: c, // 这里将Collector放到request中,这个可以对请求继续处理
ID: atomic.AddUint32(&c.requestCount, 1),
}
// 回调函数处理 request
c.handleOnRequest(request)
if request.abort {
return nil
}
if method == "POST" && req.Header.Get("Content-Type") == "" {
req.Header.Add("Content-Type", "application/x-www-form-urlencoded")
}
if req.Header.Get("Accept") == "" {
req.Header.Set("Accept", "*/*")
}
origURL := req.URL
// 这里是 去请求网络, 是调用了 `http.Client.Do`方法请求的
response, err := c.backend.Cache(req, c.MaxBodySize, c.CacheDir)
if proxyURL, ok := req.Context().Value(ProxyURLKey).(string); ok {
request.ProxyURL = proxyURL
}
// 回调函数,处理error
if err := c.handleOnError(response, err, request, ctx); err != nil {
return err
}
if req.URL != origURL {
request.URL = req.URL
request.Headers = &req.Header
}
atomic.AddUint32(&c.responseCount, 1)
response.Ctx = ctx
response.Request = request
err = response.fixCharset(c.DetectCharset, request.ResponseCharacterEncoding)
if err != nil {
return err
}
// 回调函数 处理Response
c.handleOnResponse(response)
// 回调函数 HTML
err = c.handleOnHTML(response)
if err != nil {
c.handleOnError(response, err, request, ctx)
}
// 回调函数XML
err = c.handleOnXML(response)
if err != nil {
c.handleOnError(response, err, request, ctx)
}
// 回调函数 Scraped
c.handleOnScraped(response)
return err
}
看到了, 这就是一个完整的流程。 好, 我们看一下回调函数做了什么?
func (c *Collector) handleOnRequest(r *Request) {
if c.debugger != nil {
c.debugger.Event(createEvent("request", r.ID, c.ID, map[string]string{
"url": r.URL.String(),
}))
}
for _, f := range c.requestCallbacks {
f(r)
}
}
核心就 for _, f := range c.requestCallbacks { f(r) }这句,下面我每个回调函数都介绍一下
# 回调函数
这里介绍按生命周期的顺序来介绍
# 1. OnRequest
// OnRequest registers a function. Function will be executed on every
// request made by the Collector
// 这里是注册回调函数到 requestCallbacks
func (c *Collector) OnRequest(f RequestCallback) {
c.lock.Lock()
if c.requestCallbacks == nil {
c.requestCallbacks = make([]RequestCallback, 0, 4)
}
c.requestCallbacks = append(c.requestCallbacks, f)
c.lock.Unlock()
}
// 在fetch中调用最早调用的
func (c *Collector) handleOnRequest(r *Request) {
if c.debugger != nil {
c.debugger.Event(createEvent("request", r.ID, c.ID, map[string]string{
"url": r.URL.String(),
}))
}
for _, f := range c.requestCallbacks {
f(r)
}
}
# 2. OnResponse & handleOnResponse
// OnResponse registers a function. Function will be executed on every response
func (c *Collector) OnResponse(f ResponseCallback) {
c.lock.Lock()
if c.responseCallbacks == nil {
c.responseCallbacks = make([]ResponseCallback, 0, 4)
}
c.responseCallbacks = append(c.responseCallbacks, f)
c.lock.Unlock()
}
func (c *Collector) handleOnResponse(r *Response) {
if c.debugger != nil {
c.debugger.Event(createEvent("response", r.Request.ID, c.ID, map[string]string{
"url": r.Request.URL.String(),
"status": http.StatusText(r.StatusCode),
}))
}
for _, f := range c.responseCallbacks {
f(r)
}
}
# 3. OnHTML & handleOnHTML
// OnHTML registers a function. Function will be executed on every HTML
// element matched by the GoQuery Selector parameter.
// GoQuery Selector is a selector used by https://github.com/PuerkitoBio/goquery
func (c *Collector) OnHTML(goquerySelector string, f HTMLCallback) {
c.lock.Lock()
if c.htmlCallbacks == nil {
c.htmlCallbacks = make([]*htmlCallbackContainer, 0, 4)
}
c.htmlCallbacks = append(c.htmlCallbacks, &htmlCallbackContainer{
Selector: goquerySelector,
Function: f,
})
c.lock.Unlock()
}
// 这个解析html的逻辑比较多一些
func (c *Collector) handleOnHTML(resp *Response) error {
if len(c.htmlCallbacks) == 0 || !strings.Contains(strings.ToLower(resp.Headers.Get("Content-Type")), "html") {
return nil
}
doc, err := goquery.NewDocumentFromReader(bytes.NewBuffer(resp.Body))
if err != nil {
return err
}
if href, found := doc.Find("base[href]").Attr("href"); found {
resp.Request.baseURL, _ = url.Parse(href)
}
for _, cc := range c.htmlCallbacks {
i := 0
doc.Find(cc.Selector).Each(func(_ int, s *goquery.Selection) {
for _, n := range s.Nodes {
e := NewHTMLElementFromSelectionNode(resp, s, n, i)
i++
if c.debugger != nil {
c.debugger.Event(createEvent("html", resp.Request.ID, c.ID, map[string]string{
"selector": cc.Selector,
"url": resp.Request.URL.String(),
}))
}
cc.Function(e)
}
})
}
return nil
}
# 4. OnXML & handleOnXML
// OnXML registers a function. Function will be executed on every XML
// element matched by the xpath Query parameter.
// xpath Query is used by https://github.com/antchfx/xmlquery
func (c *Collector) OnXML(xpathQuery string, f XMLCallback) {
c.lock.Lock()
if c.xmlCallbacks == nil {
c.xmlCallbacks = make([]*xmlCallbackContainer, 0, 4)
}
c.xmlCallbacks = append(c.xmlCallbacks, &xmlCallbackContainer{
Query: xpathQuery,
Function: f,
})
c.lock.Unlock()
}
func (c *Collector) handleOnXML(resp *Response) error {
if len(c.xmlCallbacks) == 0 {
return nil
}
contentType := strings.ToLower(resp.Headers.Get("Content-Type"))
isXMLFile := strings.HasSuffix(strings.ToLower(resp.Request.URL.Path), ".xml") || strings.HasSuffix(strings.ToLower(resp.Request.URL.Path), ".xml.gz")
if !strings.Contains(contentType, "html") && (!strings.Contains(contentType, "xml") && !isXMLFile) {
return nil
}
if strings.Contains(contentType, "html") {
doc, err := htmlquery.Parse(bytes.NewBuffer(resp.Body))
if err != nil {
return err
}
if e := htmlquery.FindOne(doc, "//base"); e != nil {
for _, a := range e.Attr {
if a.Key == "href" {
resp.Request.baseURL, _ = url.Parse(a.Val)
break
}
}
}
for _, cc := range c.xmlCallbacks {
for _, n := range htmlquery.Find(doc, cc.Query) {
e := NewXMLElementFromHTMLNode(resp, n)
if c.debugger != nil {
c.debugger.Event(createEvent("xml", resp.Request.ID, c.ID, map[string]string{
"selector": cc.Query,
"url": resp.Request.URL.String(),
}))
}
cc.Function(e)
}
}
} else if strings.Contains(contentType, "xml") || isXMLFile {
doc, err := xmlquery.Parse(bytes.NewBuffer(resp.Body))
if err != nil {
return err
}
for _, cc := range c.xmlCallbacks {
xmlquery.FindEach(doc, cc.Query, func(i int, n *xmlquery.Node) {
e := NewXMLElementFromXMLNode(resp, n)
if c.debugger != nil {
c.debugger.Event(createEvent("xml", resp.Request.ID, c.ID, map[string]string{
"selector": cc.Query,
"url": resp.Request.URL.String(),
}))
}
cc.Function(e)
})
}
}
return nil
}
# 5. OnError & handleOnError
这个会多次调用, 如果 err != nil情况下调用比较多, 爬虫异常的情况下,会调用
// OnError registers a function. Function will be executed if an error
// occurs during the HTTP request.
func (c *Collector) OnError(f ErrorCallback) {
c.lock.Lock()
if c.errorCallbacks == nil {
c.errorCallbacks = make([]ErrorCallback, 0, 4)
}
c.errorCallbacks = append(c.errorCallbacks, f)
c.lock.Unlock()
}
func (c *Collector) handleOnError(response *Response, err error, request *Request, ctx *Context) error {
if err == nil && (c.ParseHTTPErrorResponse || response.StatusCode < 203) {
return nil
}
if err == nil && response.StatusCode >= 203 {
err = errors.New(http.StatusText(response.StatusCode))
}
if response == nil {
response = &Response{
Request: request,
Ctx: ctx,
}
}
if c.debugger != nil {
c.debugger.Event(createEvent("error", request.ID, c.ID, map[string]string{
"url": request.URL.String(),
"status": http.StatusText(response.StatusCode),
}))
}
if response.Request == nil {
response.Request = request
}
if response.Ctx == nil {
response.Ctx = request.Ctx
}
for _, f := range c.errorCallbacks {
f(response, err)
}
return err
}
# 6. OnScraped & handleOnScraped
最后一步的回调函数处理
// OnScraped registers a function. Function will be executed after
// OnHTML, as a final part of the scraping.
func (c *Collector) OnScraped(f ScrapedCallback) {
c.lock.Lock()
if c.scrapedCallbacks == nil {
c.scrapedCallbacks = make([]ScrapedCallback, 0, 4)
}
c.scrapedCallbacks = append(c.scrapedCallbacks, f)
c.lock.Unlock()
}
func (c *Collector) handleOnScraped(r *Response) {
if c.debugger != nil {
c.debugger.Event(createEvent("scraped", r.Request.ID, c.ID, map[string]string{
"url": r.Request.URL.String(),
}))
}
for _, f := range c.scrapedCallbacks {
f(r)
}
}
注册回调函数的method还有几个没有列出来,感兴趣的,自己看一下,
上面介绍完了, 再回头看🌰
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))
})
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
一般文档解析放在html, xml 中
# 页面跳转爬取
一般处理就2种,一种是相同逻辑的页面,比如下一页,另一种,就是不同逻辑的,比如子页面
- 在
html,xml,解析出来以后,构建新的请求,我们看一下,相同页面
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// If attribute class is this long string return from callback
// As this a is irrelevant
if e.Attr("class") == "Button_1qxkboh-o_O-primary_cv02ee-o_O-md_28awn8-o_O-primaryLink_109aggg" {
return
}
link := e.Attr("href")
// If link start with browse or includes either signup or login return from callback
if !strings.HasPrefix(link, "/browse") || strings.Index(link, "=signup") > -1 || strings.Index(link, "=login") > -1 {
return
}
// start scaping the page under the link found
e.Request.Visit(link)
})
上面是 HTML的回调函数,解析页面,获取了url,使用 e.Request.Visit(link), 其实就是 e.Request.collector.Visit(link)
我解释一下
func (c *Collector) fetch(u, method string, depth int, requestData io.Reader, ctx *Context, hdr http.Header, req *http.Request) error {
defer c.wg.Done()
if ctx == nil {
ctx = NewContext()
}
request := &Request{
URL: req.URL,
Headers: &req.Header,
Ctx: ctx,
Depth: depth,
Method: method,
Body: requestData,
collector: c, // 这个上面有介绍
ID: atomic.AddUint32(&c.requestCount, 1),
}
....
}}
// Visit continues Collector's collecting job by creating a
// request and preserves the Context of the previous request.
// Visit also calls the previously provided callbacks
func (r *Request) Visit(URL string) error {
return r.collector.scrape(r.AbsoluteURL(URL), "GET", r.Depth+1, nil, r.Ctx, nil, true)
}
这种方法在实际开发中经常会用到。
- 子页面的处理逻辑
colly中主要是以
Collector为中心, 然后各种回调函数进行处理,子页面需要不同的回调函数,所以就需要新的Collector
// Instantiate default collector
c := colly.NewCollector(
// Visit only domains: coursera.org, www.coursera.org
colly.AllowedDomains("coursera.org", "www.coursera.org"),
// Cache responses to prevent multiple download of pages
// even if the collector is restarted
colly.CacheDir("./coursera_cache"),
)
// Create another collector to scrape course details
detailCollector := c.Clone()
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
log.Println("visiting", r.URL.String())
})
// On every a HTML element which has name attribute call callback
c.OnHTML(`a[name]`, func(e *colly.HTMLElement) {
// Activate detailCollector if the link contains "coursera.org/learn"
courseURL := e.Request.AbsoluteURL(e.Attr("href"))
if strings.Index(courseURL, "coursera.org/learn") != -1 {
// 子页面或其他页面
detailCollector.Visit(courseURL)
}
})
# 持久化
Collector对象有一个属性 store storage.Storage是存储的,这个是将数据直接存储下来,没有清洗。
比如, 我需要将数据持久化到数据库中,其实很简单, 在回调函数中处理。
给个例子
c.OnHTML("#currencies-all tbody tr", func(e *colly.HTMLElement) {
mysql.WriteObjectStrings([]string{
e.ChildText(".currency-name-container"),
e.ChildText(".col-symbol"),
e.ChildAttr("a.price", "data-usd"),
e.ChildAttr("a.volume", "data-usd"),
e.ChildAttr(".market-cap", "data-usd"),
e.ChildAttr(".percent-change[data-timespan=\"1h\"]", "data-percentusd"),
e.ChildAttr(".percent-change[data-timespan=\"24h\"]", "data-percentusd"),
e.ChildAttr(".percent-change[data-timespan=\"7d\"]", "data-percentusd"),
})
})
# 总结
好了,介绍完了,我没有介绍如何使用,我自己也没有写任何的代码, 我只想分享给你这种软件架构的特点以及设计模式, 希望你可以借鉴应用到工作中,一般写框架都是采用这种思维。 下面这张图很形象,爬虫框架就这些东西。

作者:若与 链接:https://www.jianshu.com/p/93187b80541f 来源:简书
不错的 colly 底层解析文章:Colly源码解析——结合例子分析底层实现_方亮的专栏-CSDN博客
# 代理的初探索
# 检测 ip
curl https://httpbin.org/ip
curl cip.cc
# 检测代理池
package ckporxy
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"log"
"net/http"
"net/url"
"os"
"sync"
"time"
)
var wg sync.WaitGroup
type Checker struct {
// 是否使用文件存储,如果为 false,则通过方法返回
IsFileSave bool
// 待检测的文件路径
ProxyFile string
// 成功的代理存储路径
PassProxyFile string
// 检测代理用的网址
CheckUrl string
// 检测超时时间,默认为 10 秒
CheckTimeout time.Duration
// 待检测的数据,如果有值,则不读取文件
ProxyData []string
// 检测通过的数据
PassProxyData []string
}
// New 创建一个检测模型
func NewChecker(options ...func(*Checker)) *Checker {
c := &Checker{}
c.Init()
for _, f := range options {
f(c)
}
return c
}
func (c *Checker) Init() {
c.ProxyFile = "./proxy.txt"
c.CheckUrl = "http://icanhazip.com"
c.PassProxyFile = "./proxy_pass.txt"
c.CheckTimeout = 10 * time.Second
c.ProxyData = nil
}
func (c *Checker) ProxyThorn(proxyAddr string) (ip string, status int) {
//访问查看ip的一个网址
proxy, err := url.Parse(proxyAddr)
if err != nil {
return
}
if proxy.Scheme == "" {
proxy.Scheme = "http"
}
netTransport := &http.Transport{
Proxy: http.ProxyURL(proxy),
MaxIdleConnsPerHost: 10,
ResponseHeaderTimeout: 5 * time.Second,
}
httpClient := &http.Client{
Timeout: c.CheckTimeout,
Transport: netTransport,
}
res, err := httpClient.Get(c.CheckUrl)
if err != nil {
//fmt.Println("错误信息:",err)
return
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
//log.Println("请求失败:",res.StatusCode)
return
}
b, _ := ioutil.ReadAll(res.Body)
return string(b), res.StatusCode
}
// 读取待检测的代理
func (c *Checker) readProxy() []string {
var data []string
file, err := os.Open(c.ProxyFile)
if err != nil {
log.Println("open ip.txt failed,err:", err)
return nil
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n') //注意是字符
if err == io.EOF {
if len(line) != 0 {
fmt.Println(line)
}
break
}
if err != nil {
fmt.Println("read file failed, err:", err)
return nil
}
line = line[:len(line)-1]
link := fmt.Sprintf("http://%s", line)
data = append(data, link)
}
return data
}
// ip验证
func (c *Checker) verification(ipInfo string) {
defer wg.Done()
var ip, status = c.ProxyThorn(ipInfo)
var result string
//判断是否有返回ip,并且请求状态为200
if status == 200 && ip != "" {
// 成功的地址写入文件
c.writeFile(ipInfo)
result = "success"
} else {
result = "fail"
}
fmt.Printf("代理:%v[检测结果:%s] \n", ipInfo, result)
}
// Check 检测代理
func (c *Checker) Check() {
//使用 goroutine 去检测 代理的可用性
var data []string
if c.ProxyData == nil {
data = c.readProxy()
} else {
data = c.ProxyData
}
for _, ipInfo := range data {
wg.Add(1)
go c.verification(ipInfo)
}
wg.Wait()
}
// 把可用的 ip 写入文件
func (c *Checker) writeFile(data string) {
file, err := os.OpenFile(c.PassProxyFile, os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0644)
if err != nil {
fmt.Println("open file failed,err", err)
return
}
defer file.Close()
_, _ = file.Write([]byte(data + "\n"))
}
# 用法
func main(){
data := []string{"http://14.97.2.106:80"...}
data = data
c := ckproxy.NewChecker()
c.CheckTimeout = 20 * time.Second
// 传入数据
c.ProxyData = data
//or 使用文件
//c.ProxyFile = "./ip.txt"
c.Check()
}